Explaining Concurrency in Go: Building a Web Scraper from Scratch
Learn Go's powerful concurrency features by building a practical web scraper that fetches multiple URLs simultaneously using goroutines, channels, and context.

Concurrency is one of Go’s most celebrated features, and for good reason. While many programming languages treat concurrent programming as an afterthought, Go was designed from the ground up to make concurrent programs simple, safe, and efficient. Whether you’re building web services that handle thousands of requests per second or data processing pipelines that coordinate multiple tasks, Go’s concurrency primitives can help you write programs that do more work in less time.
In this tutorial, we’ll explore Go’s concurrency model by building something practical: a web scraper that can check the status of multiple websites simultaneously. We’ll start with a simple, single-threaded version and gradually introduce goroutines, channels, and context to make it faster and more feature-rich. By the end, you’ll have a solid understanding of how to use Go’s concurrency tools in your own projects.
Why Concurrency Matters
Imagine you’re tasked with checking the health of 50 different websites. The straightforward approach would be to visit each site one by one, waiting for each HTTP request to complete before moving to the next. If each request takes 2 seconds, you’d be waiting 100 seconds total. That’s nearly two minutes of mostly idle time.
Now imagine if you could check all 50 sites at the same time. Instead of waiting 100 seconds, you might finish in just 3-4 seconds (limited mainly by the slowest response). This is the power of concurrent programming: the ability to perform multiple operations simultaneously rather than sequentially.
Go makes this kind of concurrent programming remarkably straightforward. Unlike languages where you need to manage threads manually or deal with complex synchronization mechanisms, Go provides lightweight “goroutines” that can be created with just the go keyword. These goroutines are managed by the Go runtime, which handles scheduling them across available CPU cores efficiently.
Why Go Excels at Concurrency
Go’s concurrency model is built around two key concepts:
- Goroutines: Lightweight threads that can run concurrently
- Channels: Type-safe communication channels that allow goroutines to coordinate and share data
This combination follows the philosophy “Don’t communicate by sharing memory; share memory by communicating.” Instead of multiple goroutines accessing the same variables (which requires complex locking), Go encourages passing data between goroutines through channels.
The web scraper we’ll build demonstrates exactly this pattern. We’ll have multiple goroutines fetching different URLs, and they’ll communicate their results back through channels. This approach is both easier to reason about and less prone to the race conditions that plague traditional threaded programs.
Setting Up the Project Environment
Before we dive into concurrent programming, let’s set up our Go environment and create the basic project structure. If you’d like, you can find all the code for this tutorial at our GitHub repository, but I highly recommend you follow along and create the files yourself.
Installing Go
If you don’t have Go installed, download it from the official Go website. Follow the installation instructions for your operating system. Once installed, verify it’s working by running:
go versionYou should see output showing your Go version.
Creating the Project
Create a new directory for our web scraper and initialize it as a Go module:
mkdir go-web-scraper
cd go-web-scraper
go mod init web-scraperSetting Up Our Target URLs
Create a file called main.go and let’s start with a list of websites to scrape:
package main
import (
"fmt"
"log"
"net/http"
"time"
)
var urls = []string{
"https://www.deepthought.sh",
"https://www.google.com",
"https://www.github.com",
"https://www.stackoverflow.com",
"https://www.reddit.com",
"https://www.wikipedia.org",
"https://www.youtube.com",
"https://www.twitter.com",
"https://www.facebook.com",
"https://www.amazon.com",
"https://www.microsoft.com",
"https://www.apple.com",
"https://www.linkedin.com",
"https://www.instagram.com",
"https://www.netflix.com",
"https://www.nytimes.com",
"https://www.cnn.com",
"https://www.bbc.com",
"https://www.medium.com",
"https://www.dropbox.com",
"https://www.spotify.com",
"https://www.salesforce.com",
"https://www.slack.com",
"https://www.airbnb.com",
"https://www.udemy.com",
"https://www.khanacademy.org",
"https://www.quora.com",
"https://www.ted.com",
"https://www.nationalgeographic.com",
"https://www.imdb.com",
}
func main() {
fmt.Println("Starting web scraper...")
// We'll add the scraping logic here
}This gives us a foundation to work with. We have a list of popular websites that should respond quickly, making them good candidates for our testing.
This tutorial assumes you’re already comfortable with Go’s basic syntax and fundamental concepts. If you’re completely new to Go, I recommend starting with A Tour of Go first. It’s an excellent introduction. Once you’ve completed it, come back to this tutorial and dive into concurrency.
Building a Simple, Single-Threaded Version
Before we introduce concurrency, let’s build a straightforward version that checks each URL sequentially. This will serve as our baseline for comparison and help us understand exactly what we’re trying to improve.
The Sequential Approach
Add this function to fetch a single URL:
func fetchURL(url string) {
start := time.Now()
resp, err := http.Get(url)
if err != nil {
fmt.Printf("[UNHEALTHY] %s - Error: %v (took %v)\n", url, err, time.Since(start))
return
}
defer resp.Body.Close()
fmt.Printf("[HEALTHY] %s - Status: %d (took %v)\n", url, resp.StatusCode, time.Since(start))
}Now update the main function to use this:
func main() {
fmt.Println("Starting web scraper...")
start := time.Now()
for _, url := range urls {
fetchURL(url)
}
fmt.Printf("\nCompleted in %v\n", time.Since(start))
}Run this version:
go run main.goYou’ll see output like:
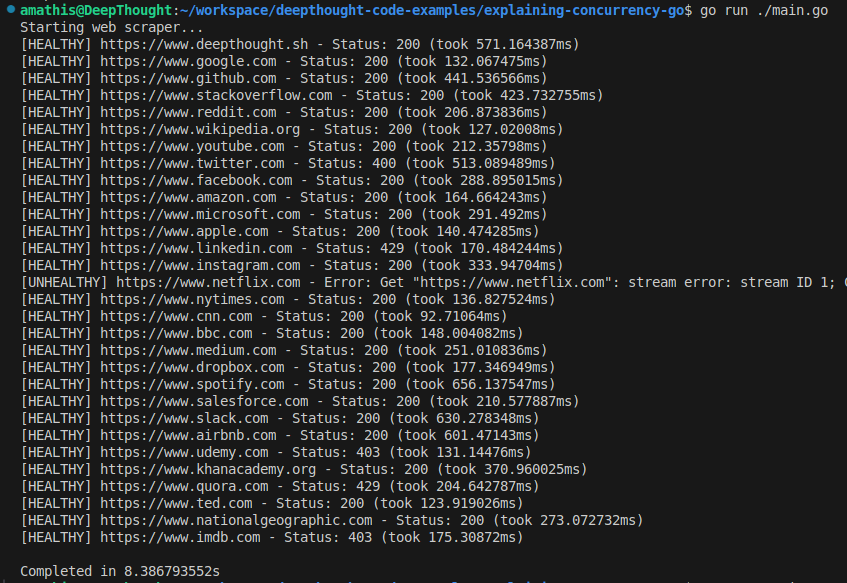
Notice how each request completes one after another. The total time of 8.4 seconds is roughly the sum of all individual request times. This is the sequential approach: simple but slow.
The Problem with Sequential Processing
The issue with this approach becomes obvious when you scale up. If you needed to check 1,000 URLs, and each takes an average of 500ms, you’d be waiting over 8 minutes. Most of that time is spent waiting for network responses, not doing actual computational work.
This is exactly the kind of problem that concurrency is designed to solve. Instead of waiting for each network request to complete before starting the next one, we can start all the requests simultaneously and collect their results as they come in.
Introducing Goroutines and WaitGroups
Now let’s transform our sequential scraper into a concurrent one using goroutines. Think of goroutines as lightweight threads that can run simultaneously within your program.
Understanding Goroutines
Goroutines are one of Go’s most powerful features. Unlike traditional threads that are managed by the operating system and consume significant memory (typically 2MB per thread), goroutines are managed by the Go runtime and start with just 2KB of memory. This means you can easily create thousands of goroutines without overwhelming your system.
Creating a goroutine is as simple as adding the go keyword before a function call:
go fetchURL(url) // This runs concurrentlyHowever, there’s a catch: the main function won’t wait for goroutines to complete. If your main function exits, all goroutines are terminated, regardless of whether they’ve finished their work.
Enter WaitGroups
To coordinate goroutines, Go provides the sync.WaitGroup type. Think of it as a counter that tracks how many goroutines are still running. You increment the counter when starting a goroutine and decrement it when the goroutine completes. The main function can then wait for the counter to reach zero.
Here’s how to use it:
First, add the sync package to your imports.
import (
"fmt"
"log"
"net/http"
"sync"
"time"
)Next, modify the fetchURL function to use a WaitGroup:
func fetchURL(url string, wg *sync.WaitGroup) {
defer wg.Done() // Decrement the counter when this function exits
start := time.Now()
resp, err := http.Get(url)
if err != nil {
fmt.Printf("[UNHEALTHY] %s - Error: %v (took %v)\n", url, err, time.Since(start))
return
}
defer resp.Body.Close()
fmt.Printf("[HEALTHY] %s - Status: %d (took %v)\n", url, resp.StatusCode, time.Since(start))
}Finally, modify the main function to use a WaitGroup:
func main() {
fmt.Println("Starting concurrent web scraper...")
start := time.Now()
var wg sync.WaitGroup
for _, url := range urls {
wg.Add(1) // Increment the counter
go fetchURL(url, &wg) // Launch goroutine
}
wg.Wait() // Wait for all goroutines to complete
fmt.Printf("\nCompleted in %v\n", time.Since(start))
}The Magic of Concurrent Execution
Run this version:
go run main.goYou’ll notice something remarkable: the total execution time is now much shorter! Instead of taking the sum of all individual request times (8.4 seconds in our case), it only takes 1.6 seconds because all the HTTP requests are happening simultaneously.
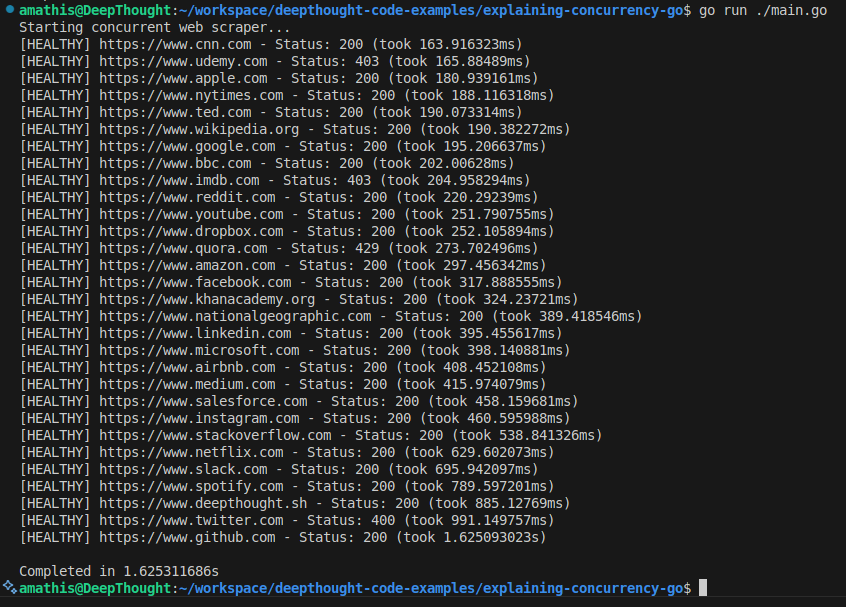
The output might look jumbled because multiple goroutines are printing at the same time, but that's actually a good sign that they're running concurrently.
Key Concepts Explained
wg.Add(1): Increments the WaitGroup counter before starting each goroutinedefer wg.Done(): Decrements the counter when the goroutine completes (defer ensures this happens even if the function exits early due to an error)wg.Wait(): Blocks until the counter reaches zero, meaning all goroutines have completed
The defer keyword is particularly important here. It ensures that wg.Done() is called regardless of how the function exits, preventing deadlocks where the main function waits forever for goroutines that never signal completion.
Collecting Results with Channels
While our concurrent scraper is faster, it has a problem: the output is jumbled because multiple goroutines are printing simultaneously. More importantly, we’re not collecting the results in a structured way that we could use for further processing.
This is where channels come in. Channels provide a way for goroutines to communicate safely and pass data between each other.
Understanding Channels
Think of channels as pipes that connect goroutines. One goroutine can send data into a channel, and another can receive it. This allows goroutines to coordinate and share information without the complexity of shared memory and locks.
Channels are typed, meaning a channel can only carry values of a specific type. For our web scraper, we’ll create a channel that carries result information.
Blocking in Channels
A key concept when working with channels is blocking. In Go, when a goroutine tries to send a value to an unbuffered channel, it blocks, meaning it waits, until another goroutine is ready to receive that value. Similarly, when a goroutine tries to receive from an empty channel, it blocks until there is data available to receive.
This blocking behavior is what enables safe communication and synchronization between goroutines without explicit locks. By coordinating through blocking sends and receives, channels help ensure that data is passed in a controlled, orderly way. Buffered channels can reduce blocking since they allow a limited number of values to be stored temporarily, letting senders proceed up to the channel’s capacity before blocking occurs.
Defining a Result Type
First, let’s define a struct to hold our results. Add this beneath the imports section of code:
type Result struct {
URL string
Status int
Error error
Duration time.Duration
}Using Channels to Collect Results
Now let’s modify our scraper to use channels. Update the fetchURL function:
func fetchURL(url string, results chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
start := time.Now()
resp, err := http.Get(url)
duration := time.Since(start)
if err != nil {
results <- Result{
URL: url,
Status: 0,
Error: err,
Duration: duration,
}
return
}
defer resp.Body.Close()
results <- Result{
URL: url,
Status: resp.StatusCode,
Error: nil,
Duration: duration,
}
}Now, update the main function:
func main() {
fmt.Println("Starting concurrent web scraper with channels...")
start := time.Now()
// Create a channel to receive results
results := make(chan Result, len(urls))
var wg sync.WaitGroup
// Start all goroutines
for _, url := range urls {
wg.Add(1)
go fetchURL(url, results, &wg)
}
// Wait for all goroutines to complete
wg.Wait()
close(results) // Close the channel when done sending
// Process all results
fmt.Println("\nResults:")
for result := range results {
if result.Error != nil {
fmt.Printf("[UNHEALTHY] %s - Error: %v (took %v)\n",
result.URL, result.Error, result.Duration)
} else {
fmt.Printf("[HEALTHY] %s - Status: %d (took %v)\n",
result.URL, result.Status, result.Duration)
}
}
fmt.Printf("\nCompleted in %v\n", time.Since(start))
}Channel Concepts Explained
make(chan Result, len(urls)): Creates a buffered channel that can hold up tolen(urls)results without blockingresults <- Result{...}: Sends a result to the channelfor result := range results: Receives all results from the channel until it’s closedclose(results): Closes the channel, signaling that no more data will be sent
The channel acts as a safe intermediary between the goroutines that produce results and the main function that consumes them. This eliminates the jumbled output problem and gives us structured data to work with.
Buffered vs Unbuffered Channels
We used a buffered channel (make(chan Result, len(urls))) that can hold multiple values. This prevents goroutines from blocking when sending results. An unbuffered channel would require a receiver to be ready immediately when a sender tries to send data.
Adding Context for Timeout and Cancellation
Real-world web scraping often involves unreliable networks and slow servers. Some requests might hang for minutes or even timeout entirely. To handle this gracefully, we’ll add timeout functionality using Go’s context package.
Understanding Context
The context package provides a standardized way to handle cancellation, deadlines, and timeouts across goroutines. Think of context as a control signal that can be passed through your program to coordinate when operations should stop.
Context is particularly useful for operations that might take a long time, like network requests. Instead of waiting indefinitely for a slow server, you can set a timeout and cancel the operation if it takes too long.
In addition to cancellation, deadlines, and timeouts, context in Go also provides a way to pass request-scoped values across API boundaries and between goroutines.
This means you can embed additional information, like authentication tokens, user IDs, or trace IDs, directly into the context object, and then retrieve it wherever needed down the call chain. This avoids using global variables and keeps data propagation explicit and safe.
Overall, context enables:
-
Cancellation signals to stop work early and free up resources.
-
Deadlines and timeouts to enforce maximum execution times.
-
Value propagation to carry metadata consistently across function calls and goroutines.
By combining these features, context helps you build responsive, efficient, and maintainable concurrent applications.
Adding Timeout to HTTP Requests
Let’s modify our scraper to include a 5-second timeout for each request. First, import the context package:
import (
"context"
"fmt"
"net/http"
"sync"
"time"
)Next, modify the fetchURL to add a timeout for each request:
func fetchURL(url string, results chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
start := time.Now()
// Create a context with 5-second timeout
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
// Create request with context
req, err := http.NewRequestWithContext(ctx, "GET", url, nil)
if err != nil {
results <- Result{
URL: url,
Status: 0,
Error: err,
Duration: time.Since(start),
}
return
}
// Use default client to make the request
client := &http.Client{}
resp, err := client.Do(req)
duration := time.Since(start)
if err != nil {
results <- Result{
URL: url,
Status: 0,
Error: err,
Duration: duration,
}
return
}
defer resp.Body.Close()
results <- Result{
URL: url,
Status: resp.StatusCode,
Error: nil,
Duration: duration,
}
}Global Cancellation
While individual timeouts are useful, sometimes you might want to control all requests together. For example, you may want to stop all ongoing fetches after a total of 10 seconds (e.g., if the user cancels or your app is shutting down).
To do this, we can create a shared parent context in main, and pass it into each fetchURL function. Let’s slightly adjust fetchURL to accept an external context:
func fetchURL(ctx context.Context, url string, results chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
start := time.Now()
req, err := http.NewRequestWithContext(ctx, "GET", url, nil)
if err != nil {
results <- Result{
URL: url,
Status: 0,
Error: err,
Duration: time.Since(start),
}
return
}
client := &http.Client{}
resp, err := client.Do(req)
duration := time.Since(start)
if err != nil {
results <- Result{
URL: url,
Status: 0,
Error: err,
Duration: duration,
}
return
}
defer resp.Body.Close()
results <- Result{
URL: url,
Status: resp.StatusCode,
Error: nil,
Duration: duration,
}
}Now update main:
func main() {
fmt.Println("Starting concurrent web scraper with global cancellation...")
start := time.Now()
// Create a parent context with a 10-second timeout for all requests
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
results := make(chan Result, len(urls))
var wg sync.WaitGroup
for _, url := range urls {
wg.Add(1)
go fetchURL(ctx, url, results, &wg)
}
wg.Wait()
close(results)
fmt.Println("\nResults:")
for result := range results {
if result.Error != nil {
fmt.Printf("[UNHEALTHY] %s - Error: %v (took %v)\n", result.URL, result.Error, result.Duration)
} else {
fmt.Printf("[HEALTHY] %s - Status: %d (took %v)\n", result.URL, result.Status, result.Duration)
}
}
fmt.Printf("\nCompleted in %v\n", time.Since(start))
}Benefits of Context
- Prevents hung requests: Operations that take too long are automatically cancelled
- Graceful shutdown: You can cancel all ongoing operations when shutting down your program
- Resource management: Cancelled operations free up resources immediately
- Cascading cancellation: If a parent context is cancelled, all child contexts are cancelled too
Enhancing Output and Result Processing
Now that we have a working concurrent scraper with timeout handling, let’s improve how we present the results. Instead of just printing each result as it comes in, we’ll collect and summarize the data in a more useful format.
Aggregating Results
Let’s modify our result processing to provide summary statistics:
func main() {
fmt.Println("Starting concurrent web scraper with global cancellation...")
start := time.Now()
// Create a parent context with a 10-second timeout for all requests
ctx, cancel := context.WithTimeout(context.Background(), 10*time.Second)
defer cancel()
results := make(chan Result, len(urls))
var wg sync.WaitGroup
for _, url := range urls {
wg.Add(1)
go fetchURL(ctx, url, results, &wg)
}
wg.Wait()
close(results)
// Collect and categorize results
var successful, failed []Result
var totalDuration time.Duration
for result := range results {
totalDuration += result.Duration
if result.Error != nil {
failed = append(failed, result)
} else {
successful = append(successful, result)
}
}
// Print detailed results
fmt.Println("\n=== SUCCESSFUL REQUESTS ===")
for _, result := range successful {
fmt.Printf("[HEALTHY] %s - Status: %d (took %v)\n",
result.URL, result.Status, result.Duration)
}
if len(failed) > 0 {
fmt.Println("\n=== FAILED REQUESTS ===")
for _, result := range failed {
fmt.Printf("[UNHEALTHY] %s - Error: %v (took %v)\n",
result.URL, result.Error, result.Duration)
}
}
// Print summary
fmt.Printf("\n=== SUMMARY ===\n")
fmt.Printf("Total URLs: %d\n", len(urls))
fmt.Printf("Successful: %d\n", len(successful))
fmt.Printf("Failed: %d\n", len(failed))
fmt.Printf("Success rate: %.1f%%\n", float64(len(successful))/float64(len(urls))*100)
fmt.Printf("Total time: %v\n", time.Since(start))
if len(successful) > 0 {
fmt.Printf("Average response time: %v\n", totalDuration/time.Duration(len(successful)))
}
}This provides a much more useful output format that separates successful and failed requests and includes summary statistics.
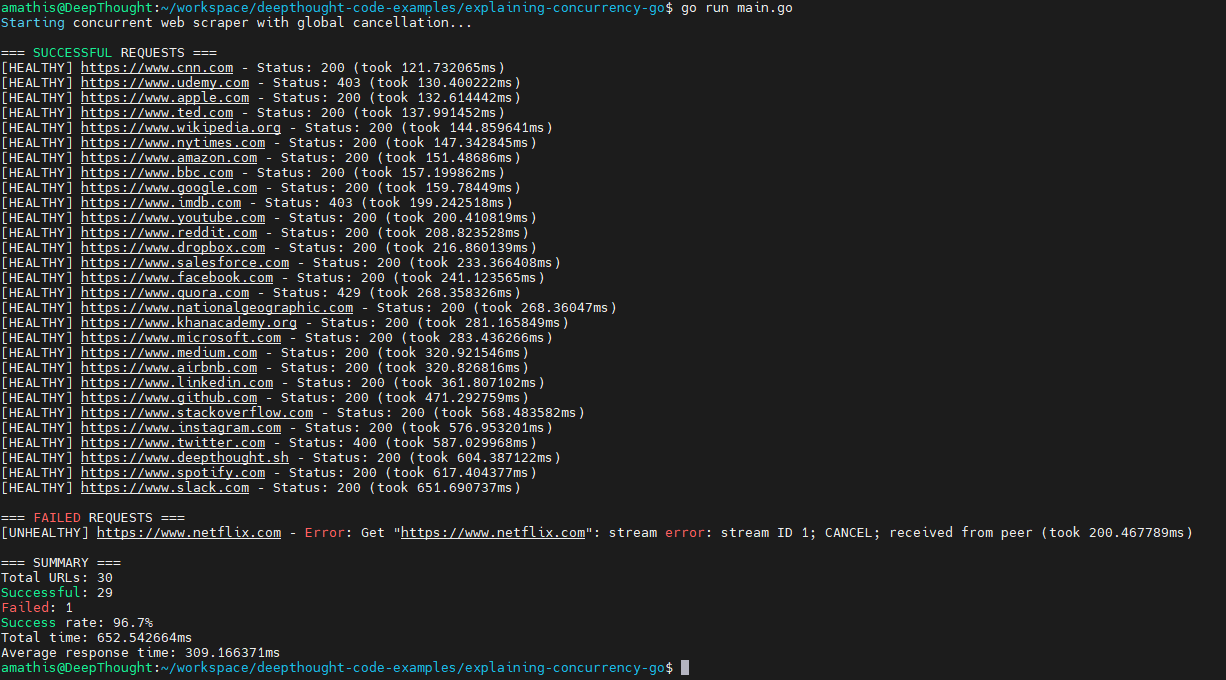 The output might look jumbled because multiple goroutines are printing at the same time, but that's actually a good sign that they're running concurrently.
The output might look jumbled because multiple goroutines are printing at the same time, but that's actually a good sign that they're running concurrently.
Limiting Concurrency with Worker Pools
While our scraper is now capable of running all requests concurrently, there are situations where you might want to limit the number of simultaneous requests. For example, you could be scraping a server with rate limits or trying to avoid overwhelming your own system resources.
This is where worker pools come in.
Understanding Worker Pools
A worker pool is a concurrency pattern that allows you to control the number of goroutines running at the same time. Instead of launching a goroutine for every task, you create a fixed number of workers that process tasks from a shared queue. This approach ensures that your program doesn’t exceed a predefined level of concurrency.
Think of it like a restaurant kitchen: instead of having every chef cook their own dish simultaneously (which could overwhelm the kitchen), you assign tasks to a limited number of chefs who work on them one at a time. The tasks are queued, and each chef picks up the next task when they’re free.
Implementing Worker Pools
To implement a worker pool, we need three main components:
- A
workerPoolfunction to manage workers and distribute tasks. - A
workerfunction that fetches URLs using the existing fetchURL logic. - A
processResultsfunction to aggregate and summarize the results.
The worker pool will consist of:
- A jobs channel: This holds the URLs to be processed.
- A results channel: This will be passed from main collects the results from each worker.
- A fixed number of workers: Each worker processes one URL at a time.
Creating the Worker Pool
The workerPool function will manage the workers and distribute tasks. It accepts a list of URLs, the number of workers, and a results channel. The jobs channel acts as a queue for URLs, and workers pull tasks from this queue.
func workerPool(urls []string, numWorkers int, results chan Result) {
jobs := make(chan string, len(urls))
// Start workers
var wg sync.WaitGroup
for i := 0; i < numWorkers; i++ {
wg.Add(1)
go worker(jobs, results, &wg)
}
// Send jobs
for _, url := range urls {
jobs <- url
}
close(jobs)
// Wait for workers to finish
wg.Wait()
}Creating the Worker Function
The worker function processes tasks from the jobs channel. Each worker fetches URLs using the fetchURL function and sends the results to the results channel. The worker function runs in its own goroutine and exits when the jobs channel is closed.
func worker(jobs <-chan string, results chan<- Result, wg *sync.WaitGroup) {
defer wg.Done()
for url := range jobs {
start := time.Now()
ctx, cancel := context.WithTimeout(context.Background(), 5*time.Second)
defer cancel()
req, err := http.NewRequestWithContext(ctx, "GET", url, nil)
if err != nil {
results <- Result{URL: url, Error: err, Duration: time.Since(start)}
continue
}
client := &http.Client{}
resp, err := client.Do(req)
duration := time.Since(start)
if err != nil {
results <- Result{URL: url, Error: err, Duration: duration}
continue
}
resp.Body.Close()
results <- Result{
URL: url,
Status: resp.StatusCode,
Duration: duration,
}
}
}Aggregating Results
The processResults function collects and categorizes results from the results channel. It separates successful and failed requests, calculates summary statistics, and displays detailed output.
func processResults(results <-chan Result) {
var successful, failed []Result
var totalDuration time.Duration
for result := range results {
if result.Error != nil {
failed = append(failed, result)
} else {
successful = append(successful, result)
totalDuration += result.Duration // Sum of individual request durations
}
}
// Print detailed results
fmt.Println("\n=== SUCCESSFUL REQUESTS ===")
for _, result := range successful {
fmt.Printf("[HEALTHY] %s - Status: %d (took %v)\n",
result.URL, result.Status, result.Duration)
}
if len(failed) > 0 {
fmt.Println("\n=== FAILED REQUESTS ===")
for _, result := range failed {
fmt.Printf("[UNHEALTHY] %s - Error: %v (took %v)\n",
result.URL, result.Error, result.Duration)
}
}
// Print summary
fmt.Printf("\n=== SUMMARY ===\n")
fmt.Printf("Total URLs: %d\n", len(successful)+len(failed))
fmt.Printf("Successful: %d\n", len(successful))
fmt.Printf("Failed: %d\n", len(failed))
fmt.Printf("Success rate: %.1f%%\n", float64(len(successful))/float64(len(successful)+len(failed))*100)
fmt.Printf("Total time (sum of request durations): %v\n", totalDuration)
if len(successful) > 0 {
fmt.Printf("Average response time: %v\n", totalDuration/time.Duration(len(successful)))
}
}Integrating Worker Pool into Main
Finally, the main function ties everything together. It initializes the results channel, calls the workerPool function, and processes the results using processResults.
func main() {
fmt.Println("Starting web scraper with worker pool and summary...")
start := time.Now()
numWorkers := 5 // Limit concurrency to 5 workers
results := make(chan Result, len(urls))
workerPool(urls, numWorkers, results)
close(results) // Close the results channel after workerPool completes
processResults(results)
// Print the actual elapsed time
fmt.Printf("\nCompleted in %v\n", time.Since(start))
}
Testing the Worker Pool
Run the updated scraper:
go run main.goYou’ll notice that only 5 requests are processed at a time, even though there are more URLs in the queue. This controlled concurrency ensures that your program runs efficiently without overwhelming the system.
Extending the Worker Pool
Now that we have a basic worker pool, here are some ideas for extending it:
- Dynamic Worker Count: Adjust the number of workers based on system load or server response times.
- Retry Logic: Add retries for failed requests to improve reliability.
- Priority Queue: Process high-priority URLs first by using a priority queue instead of a simple channel.
Worker pools are a powerful pattern for managing concurrency in Go. By limiting the number of simultaneous goroutines, you can build systems that are both efficient and scalable.
Wrapping Up
In this tutorial, we’ve built a practical web scraper from the ground up while learning Go’s core concurrency concepts. We started with a simple sequential version and gradually introduced goroutines, channels, and context to create a fast, reliable concurrent program.
The key takeaways from this journey:
- Goroutines make it trivial to run multiple operations simultaneously. They’re lightweight and managed by the Go runtime, so you can create thousands without worrying about system resources.
- Channels provide a safe way for goroutines to communicate. Instead of sharing memory between threads (which requires complex locking), Go encourages passing data through channels.
- Context gives you fine-grained control over cancellation and timeouts. This is essential for network operations that might hang or take too long.
- WaitGroups help coordinate multiple goroutines, ensuring your program doesn’t exit before all concurrent work is complete.
These concepts form the foundation of concurrent programming in Go. Whether you’re building web servers, data processing pipelines, or any other concurrent system, these patterns will serve you well.
The web scraper we built demonstrates real-world application of these concepts, but the same patterns apply to many other domains. You might use similar techniques to process files in parallel, handle multiple database queries simultaneously, or coordinate microservices.
Go’s concurrency model makes it possible to write programs that are both fast and easy to understand. By following the principle of “don’t communicate by sharing memory; share memory by communicating,” you can build concurrent systems that are less prone to the race conditions and deadlocks that plague traditional threaded programs.
As you continue exploring Go, you’ll find these concurrency primitives appearing throughout the ecosystem. Web frameworks use them to handle multiple requests simultaneously, database drivers use them to manage connection pools, and distributed systems use them to coordinate across multiple machines.
The skills you’ve gained here will serve you well as you explore more advanced topics and build even more ambitious projects.
Further Reading
To deepen your understanding of Go’s concurrency features, here are some excellent resources:
Official Go Documentation
- Go Concurrency Patterns - Advanced patterns for concurrent programming
- Effective Go - Concurrency - Best practices for concurrent Go code
- Go Memory Model - Understanding how Go handles memory in concurrent programs
Key Concepts to Explore Next
- Select statements: Handle multiple channel operations
- Context package: Advanced cancellation and timeout patterns
- Worker pools: Manage concurrency with limited resources
- Rate limiting: Control request frequency to external services
- Mutexes and atomic operations: When you need shared state
Additional Learning Resources
- Go by Example - Goroutines
- Go by Example - Channels
- Concurrency in Go (O’Reilly) - Comprehensive book on Go concurrency

Aaron Mathis
Systems administrator and software engineer specializing in cloud development, AI/ML, and modern web technologies. Passionate about building scalable solutions and sharing knowledge with the developer community.
Related Articles
Discover more insights on similar topics